





我们已经介绍过很多仅用RGB相机进行动作捕捉的研究了,其中大多数是模拟出骨骼进行追踪,少数则是通过模拟出的骨骼套上一个粗糙的模型,便可称为3D模型了。
近日,Facebook AI Reaserch(FAIR)开源了一项将2D RGB图像的所有人类像素实时映射至3D模型的技术——DensePose,而且采用的也不是我们经常介绍的骨骼追踪,而是一种十分密集的方案追踪来构建3D模型。
在户外和穿着宽松衣服的 也表现良好。

还支持多人同时追踪。

那这个密集如何来理解呢?
对于一般的骨骼追踪,追踪的点大多在十到二十个之间,再多也没有多少实际的效果。而DensePose所追踪的点一共有336个,密密麻麻全身都是点。(密集恐惧症退避)

之所以要追踪这么多的点,是构建一个平滑流畅的3D模型所必须的数据。
辛苦的付出也是值得的,DensePose无论是在户外还是多人下都表现良好,还能实时更换场景中人的衣服。
那就来看看他们是怎么做到的吧。
为了让机器可以学习,研究人员手动标记了5万张照片中的336个点,光这个步骤就是一个巨大的工程了,如果按部就班的标记注释,不知道要到什么时候完成了。

研究人员将一个人拆分成了24个部分,分别为头、躯干上部、躯干下部、大臂、小臂、大腿、小腿、手、脚。每个部分标记14的点。

对于头部、手部、脚部都由人手动标记。同时还要求注释者在标记的时候标出被衣物掩盖住的部位,比如宽松的裙子。

这些工作做完后进入第二阶段,研究人员对每一个展开部位区域进行采样,会获得6个不同的标记图,提供二维坐标地图使标记者更直观的判断哪个标记是正确的。
最后再将平面重新组合成3D模型,进行最后一步校准。
这样两步下来,研究人员得以高效准确的获得了准确的标记。不过在躯干、背部还有 臀部有较大的误差。

接下来就是深度学习的阶段了,这时一个好的方案就好比性能优越的催化剂。
研究人员采用与Mask-RCNN架构的DenseReg类似的方法,构成了'DensePose-RCNN'系统,还进一步开发使得训练的准确度提高。首先由外观粗略的估算像素所在的位置,然后将其与准确的坐标对齐。
DenseReg MaskRCNN的关键点分支中使用相同的体系结构,由8个交替的3×3完全卷积和512个通道的ReLU层组成。得益于Caffe2,所产生的架构实际上与Mask-RCNN一样快。

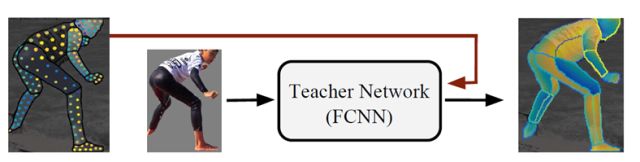
为了降低错误率,还训练了一个“教师”网络来重建地面,部署它完整的图像域,产生一个密集的监督信号。研究人员将人类监督者半自动监督和“教师网络”进行对比,结果是“教师”完胜。
研究人员还将其方法与SMPLify进行了对比,在模型的模拟方面,研究人员的自下而上的前馈方法在很大程度上胜过了迭代的模型拟合结果。

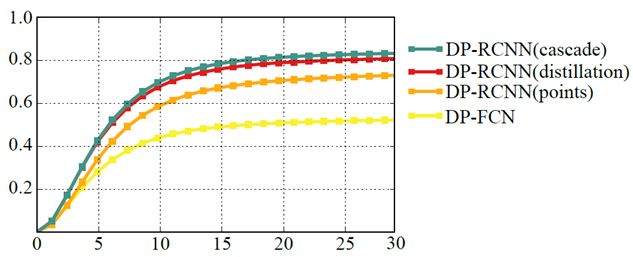
同时在多人处理时,FCN明显差于'DensePose-RCNN,再与其他方案比较时优势也十分突出。
最后,整体呈现的效果如开头所讲,能够处理大量遮挡物,成功的模拟出了衣服后面的人,但有一点需要注意,那就是所有人都是通过固定的曲率拟合的。而且在多人状况下表现十分良好。




