




N-gram语言模型是基于自然语言统计处理方法实现的,假设给定一段语言的文本: 
其统计先验概率可以表示如下:
当  时,
时,  ,称为一阶语言模型,
,称为一阶语言模型, 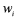 可以是字、词语或词类等等,称为统计基元,一般表示的是词。
可以是字、词语或词类等等,称为统计基元,一般表示的是词。
 的先验概率由
的先验概率由  决定,若由
决定,若由  组成的一个特定序列,这个序列称为
组成的一个特定序列,这个序列称为  的历史。
的历史。
对于N-gram语言模型来说,通常会默认在一句话的收尾两端增加两个标志:“<BOS>”,“<EOS>”,
表示一句话的开始和结束,则  可以写成如下形式:
可以写成如下形式: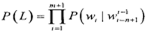
![]()
 表示词序列
表示词序列 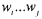 ,
,  表示<BOS>,
表示<BOS>,  表示<EOS>。
表示<EOS>。
 可以用相对频率计算概率的方法得到:
可以用相对频率计算概率的方法得到:
当n=1时,表示基元 ![]() 与
与 ![]() 之前的字符串相互独立,称为uni-gram(1-gram),当n=2时,称为Bigram(2-gram),也称为1阶马儿可夫链,当n=3时,称为Trigram(3-gram),也称为2阶马儿可夫链。
之前的字符串相互独立,称为uni-gram(1-gram),当n=2时,称为Bigram(2-gram),也称为1阶马儿可夫链,当n=3时,称为Trigram(3-gram),也称为2阶马儿可夫链。
以上是三种通常使用的N-gram模型。N元语言模型的最大优点是求解方法简单有效,通过大规模的数据统计即可得到较好的实际效果。目前普通话大词汇量连续语音识别系统常用基于词的Bigram和Trigram进行解码。
1. 连续字词N-gram值特点
N-gram概率值反映的是字或词间持续关系紧密度。如果某个字或词点的N-gram值较高,可能表示该点前后搭配非常紧密;如果某个字或词点的N-gram值较低,可能表示该点前后搭配并不紧密,可能是错误的点。但是,许多正确的字却可能因为是词与词的交界,其N-gram值也比较低,但该字是后一个二字词的第一个字。例如“说什么没听懂”,“说什么”的N-gram值是-3.3640,“没听懂”的N-gram值是-3.9768,但“什么没”的N-gram值是-5.7797.这里并不能简单地就认定“什么没”就是识别结果错误点。
这种情况下如果下一个字的N-gram值较高,我们认为这个字并非识别错误。相反,出现连续低点的情况,更容易确定该字识别错误。
为了后续做阈值分析判定 , 需要选择是字或词的N-gram值前一个还是和后一个之间进行判定更具有区分性,后面还需具体分析, 得出合适的前后相邻点作阈值判定依据 。
2. N-gram值连续低点分析
如果连续两个或者两个以上点的出现连续较低的N-gram值,此处出现识别错误的概率较高,我们有理由认为该点为可能出错点 。由N-gram图分析易知,绝大多数情况下,一个句子的N-gram值应该是正常的上下高低交错起伏,并且在一定范围内波动 , 连续超过一定范围的低点往往是错误的地方。根据这一分析结果 ,我们将此作为判断句子识别错误位置的首要依据。
出现错误的位置中除了错音还可能会出现吞音、添音的情况,都可能导致该情况有变化,这里都认为该点出错。
下面以一个例句为例:
正确句子:好的不需要我已经有了

图1 正确句子的N-gram连线图
错误句子:那谁关联申过的

图2 错误句子的N-gram连线图
从图中可以看到 , 原来正确的句子的折线在一定范围内上下波动 , 但识别错误的句子在句子末尾处出现严重的连续下降。这种现象对于确定语音识别错误提供了重要依据。发掘这种N-gram接续值的连续低点有助于快速确定语音识别错误。
3. N-gram值高低点波动幅度分析
正确句子字词前后之间一定有一定的搭配,所以波动幅度会在一定范围内。而且,因为汉字要是双字词 , 所以N-gram图中的连线会看起来是交替的高低起伏。这种情况下 , 尽管有N-gram值会高低起落,但大致是高低交错起落 , 而且在一定区间上下波动,具有一定的幅度 。而对于错误识别句子来说,上下浮动的幅度非常大 。通过训练阈值 , 得到合适的上下浮动的幅度范围 , 就很容易确定在幅度或者N-gram值不是高低交错而是连续下降的点为识别错误的可疑点 。
4. 连续N-gram分析和评价
如果某点的N-gram值较低,低于某个阈值,该点很有可能是语音识别错误的地方;如果某点的N-gram值较高,高于某个阈值,该点很有可能是正确的字,如果能和相邻的正确字组成词,我们称之为锚点词。但是仅仅是高于或者低于某个阈值就判断是识别正确或错误可靠性不够高,需要进一步的方法排除误判的情形。采取的方法包括对数据进行平滑,综合比较二元和三元的区分效果。除此之外还有以下方法:
4.1. 连续N-gram值低点
如果连续两个或者两个以上点的出现连续较低的N-gram值 , 此处出现识别错误的概率较高,我们有理由认为该点为可以出错点。实际情况中除了错音还可能会出现吞音,添音的情况,都认为该点出错 。
4.2. 相邻N-gram值分析
如果某个点的N-gram值较低,许多正确的字可能因为例如是词与词的交界,其N-gram值较低,但该字可能与后面的字结合更紧密,即该字是二字词的第一个字,这种情况下如果下一个字的N-gram值较高,我们认为这个字并非识别错误。相反,出现连续低点的情况,更易确定该字识别错误。
4.3. 点位锚点词
在语音识别纠错中,除了要发现错误的字词,发现可靠性非常高的正确字词也很重要,这些正确字词称之为锚点词。确定了锚点词,就能确定句子的语境,句子结构等重要信息,从而为纠错提供纠正方向和纠正依据 。
对于连续N-gram值较高的点,可以通过组成词来确定为锚点词 。对于锚点词,尽可能的要发现的多,最重要的是准确率必须足够高,否则反而会对纠错造成误导。
5. 基于N-gram模型的主动学习方法探究
在N-gram模型训练建模中,估计模型参数需要非常多的有标注语音识别后文本数据。随着智能语音交互平台规模增加及完善,很容易收集大量无标注的语音识别后文本数据,主要是没有标注。为了节约对大量文本标注的成本及提高建模效率,主动学习提供的方法是一个很好的思路,可以间接实现对文本数据的标准,将其应用于语音识别后文本检测以及纠错,并期望能实现接近大语料训练得到的系统性能。
在建立好基线系统后,在语言模型训练层面上借助主动学习方法继续进行模型优化。首先,采用N-gram值连续低点准则和N-gram值高低点幅度准则实现对大量无标注数据的选择,合理地从无标注数据中挑选语音识别准确度较高的文本语料,然后将筛选得到的无标注数据与原有标注数据一起训练语言模型参数。其次,在语言,模型训练的最后一次模型参数更新时,仅采用语音识别后文本集合中有标注语料来进行模型参数的精细迭代优化。
这种半监督数据选择方法的具体实现方案借助了语言模型性能评测的概念,使用N-gram值连续低点准则和N-gram值高低点幅度准则选择符合训练需求的无标注(无监督)文本参与模型的优化训练,基于N-gram值连续低点准则和N-gram值高低点幅度准则的数据选择方法原理结构如图3所示

图3基于N-gram值连续低点准则和高低点幅度准则的数据选择方法原理结构图
如图3所示,首先利用已知的少量有准确标注数据(精标数据)训练一个起始的种子模型(语言模型(LM)),也可以称为引导模型;然后,利用得到的种子LM模型,对大量的无标注数据进行N-gram值提取,会得到所有无标注文本数据的N-gram值连续低点准则和N-gram值高低点幅度准则(类标注),实验中,根据N-gram值的计算公式,采用种子LM作为原有少量有准确标注数据的文本计算参考模型,将大量无标注文本数据作为测试文本数据,计算大量无标注文本数据与原有少量有准确标注数据的N-gram值连续低点准则和N-gram值高低点幅度准则,设置相应的阈值,将满足阈值的文本数据筛选出来。
完成对大量无标注数据的选择之后,将基于N-gram值连续低点准则和N-gram值高低点幅度准则筛选出来无标注数据与原少量有准确标注数据一起参加N-gram语言模型的训练。


